LBRAI2222 - Compléments de biométrie et plans expérimentaux
Résumé de section
-
Bienvenue sur le site du cours Compléments de biométrie et plans expérimentaux, qui prolonge le cours de Modélisation et exploration des données multivariées (LBIRA2110).
Ce cours aborde les modèles linéaires mixtes, largement utilisés en expérimentation agronomique, qui permettent de décomposer les différentes sources de variabilité, de les modéliser pour améliorer l'inférence sur les effets de facteurs contrôlés et de les prendre en considération dans le design d'expériences. Il aborde d'autres aspects de la planification d'expériences en R&D.
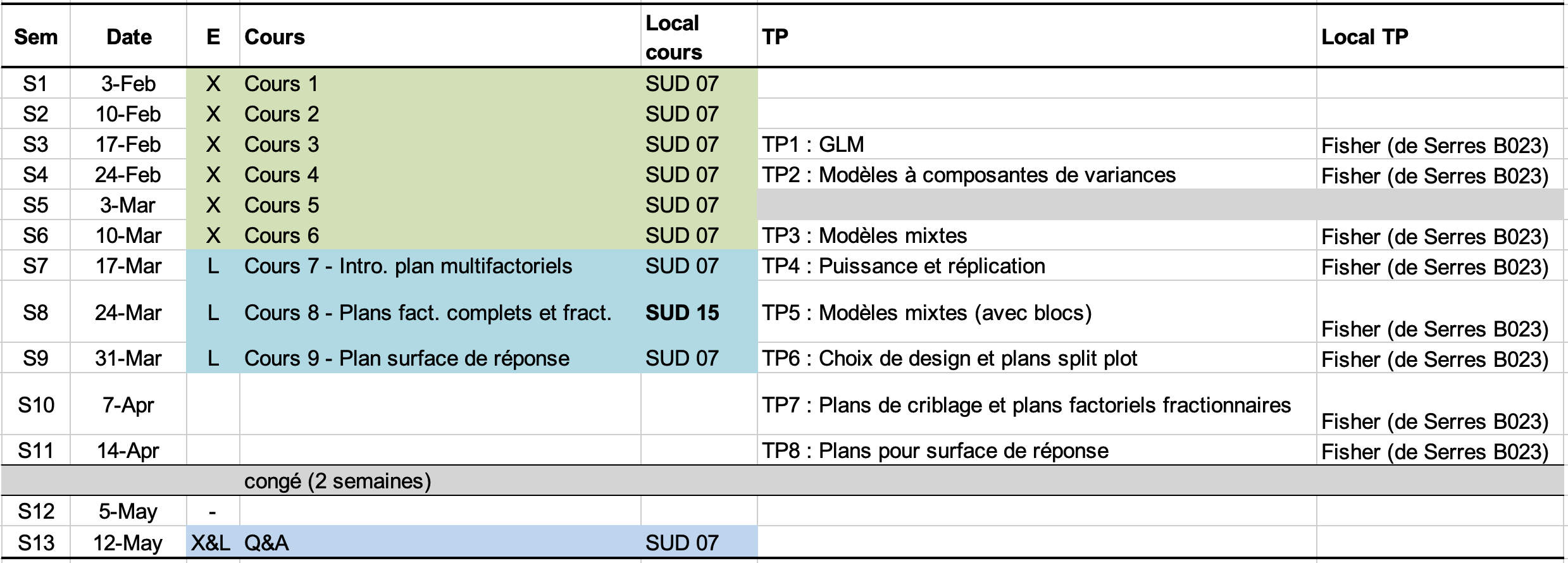
Le cours 2025 commencera en semaine S1 le lundi 3 février 2025 à 8h30 au SUD07. Le calendrier du cours se trouve ci-dessous et vous trouverez ici toutes les informations pratiques et documents liés.
Très bon quadrimestre à tous et toutes
Votre équipe: Nicolas Biot, Laura Symul et Xavier Draye
-
-
Les étudiants doiventRemettre un travail
-
-
Les étudiants doiventMarquer comme terminé4.7 Mo · Déposé le 29 avr. 24, 19:24
-
-
Dossier pour examen Aout 2025
-